DataStorage » History » Version 4
« Previous -
Version 4/16
(diff) -
Next » -
Current version
Anonymous, 10/05/2007 10:16 PM
= Data Storage =
This page describes the design of the database that is/will be used in order to store all necessary pieces information that are obtained from the "stand-alone" ProCKSI ''core'' application (see [wiki:DataStandardisation]).
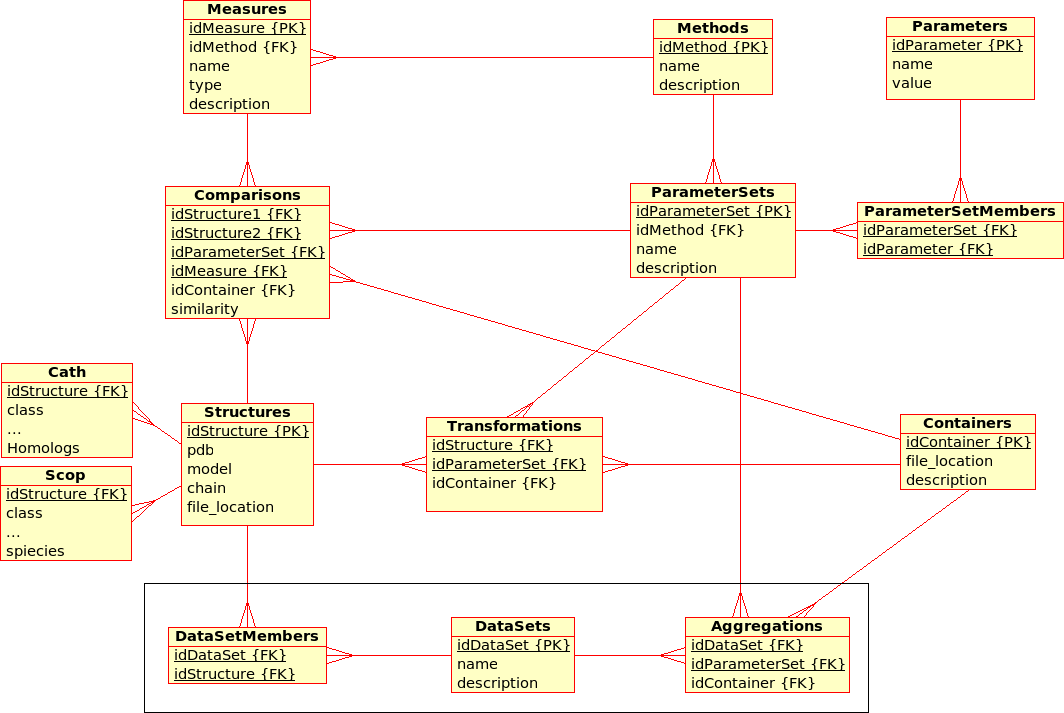
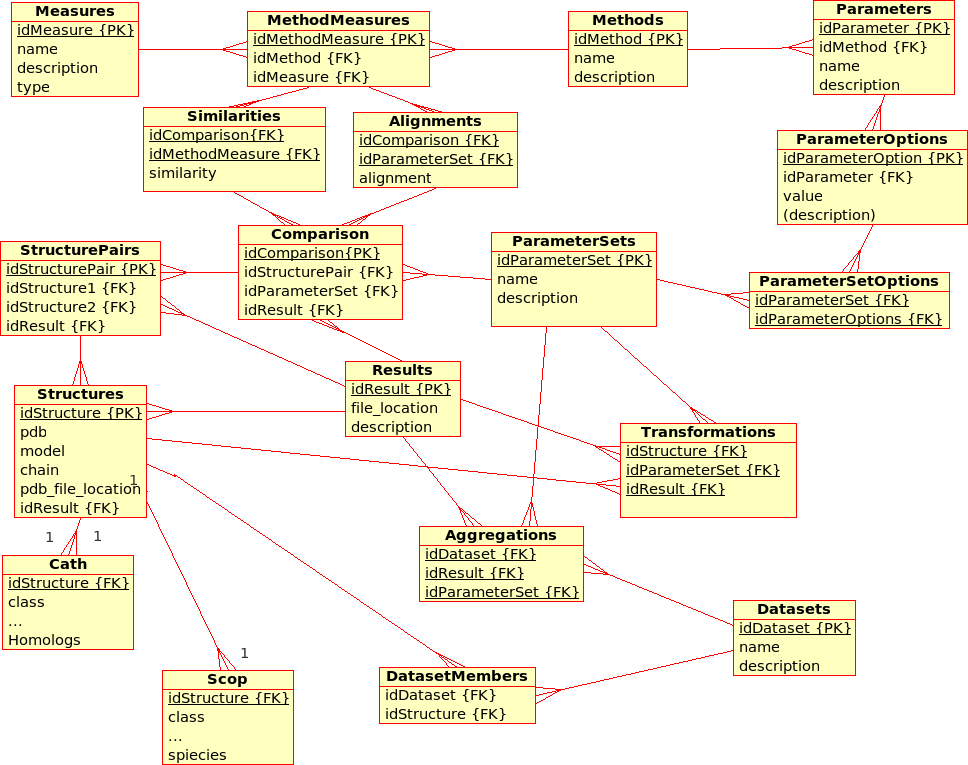
Database Design for the (static) Protein MultiverseImage(ProteinMultiverseDataBase.png)
'''Explenation of the database design''':
* There are multiple similarity comparison ''Methods'': e.g. USM, MaxCMO, DaliLite, ...
* There are multiple similarity ''Measures'': e.g. Z-score, TM-score, Number of Alignments, ...
* Some ''Methods'' produce ''Measures'' with the same name, but not necessarily the same meaning: e.g. DaliLite/Z, TMalign/Z, ...br
Thus, a ''!MethodMeasures'' relation is necessary.
- Each ''Method'' can have multiple (different) ''Parameters'': e.g. USM/Compressor, USM/Equation, ...
- Each ''Method'' can have multiple (different) ''!ParameterOptions'': USM/Compressor/bzip, USM/Compressor/gzip, ...
- A "!ParameterSet" is used to calculate the ''Similarity'' of ''!StructurePairs''. It is a collection of specific ''!ParameterSetOptions''. If a ''Method'' does not use any parameters, it is not included in the ''!ParameterSet'', but accessible via the ''!MethodMeasure'' relation.
- The ''!StructurePairs'' relation holds all possible combinations of ''Structures'', and a link to a further ''Results'' file in XML format. This file may contain results for multiple ''!StructurePairs'', e.g. alignments, matrices, etc.
- Each ''Structure'' is uniquely determined by its PDB code, model and chain. (Domains are not taken into accout yet.) The location of the PDB file is given and a link to a further ''Results'' file in XML format. This file may contain additional information for multiple ''Structures'', e.g. sequence, secondary structure, experimental resolution, ...
- Each ''Structure'' is extended by further classifiction information from ''CATH'' and ''SCOP''.
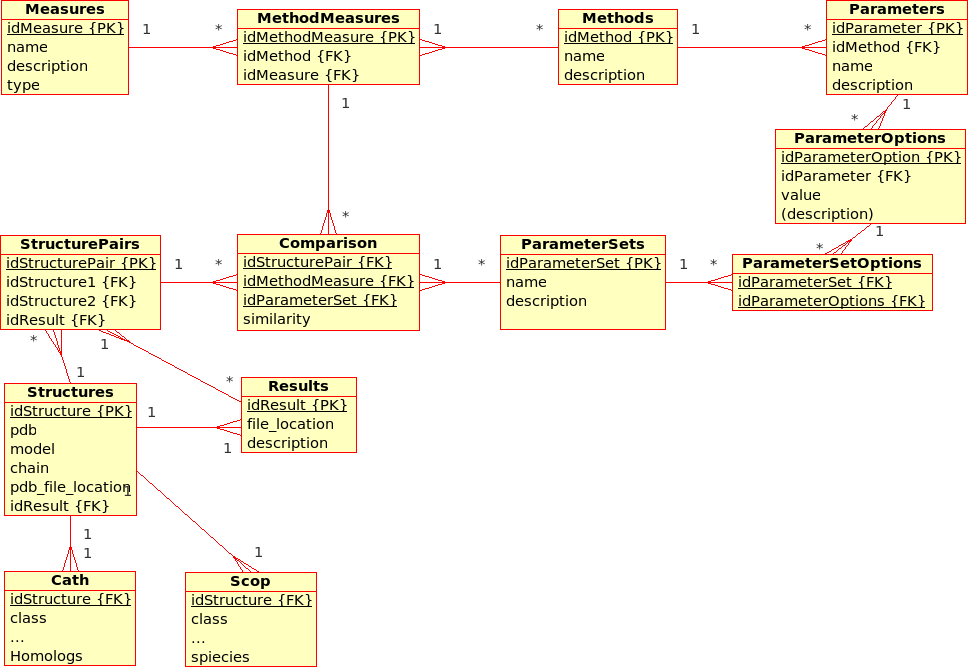
Image(ProteinMultiverseDataBaseExt1.png)
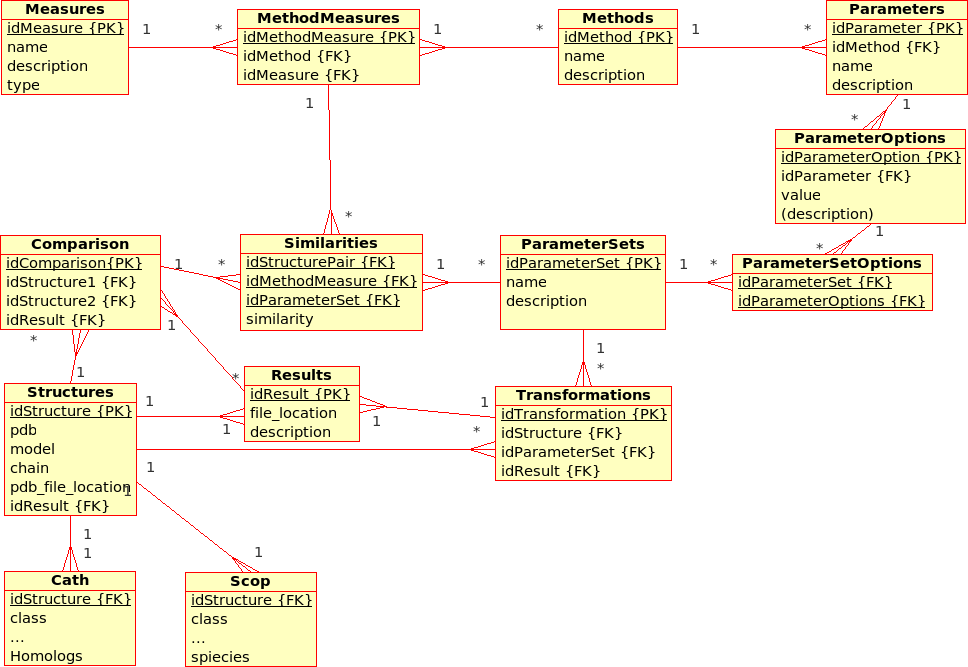
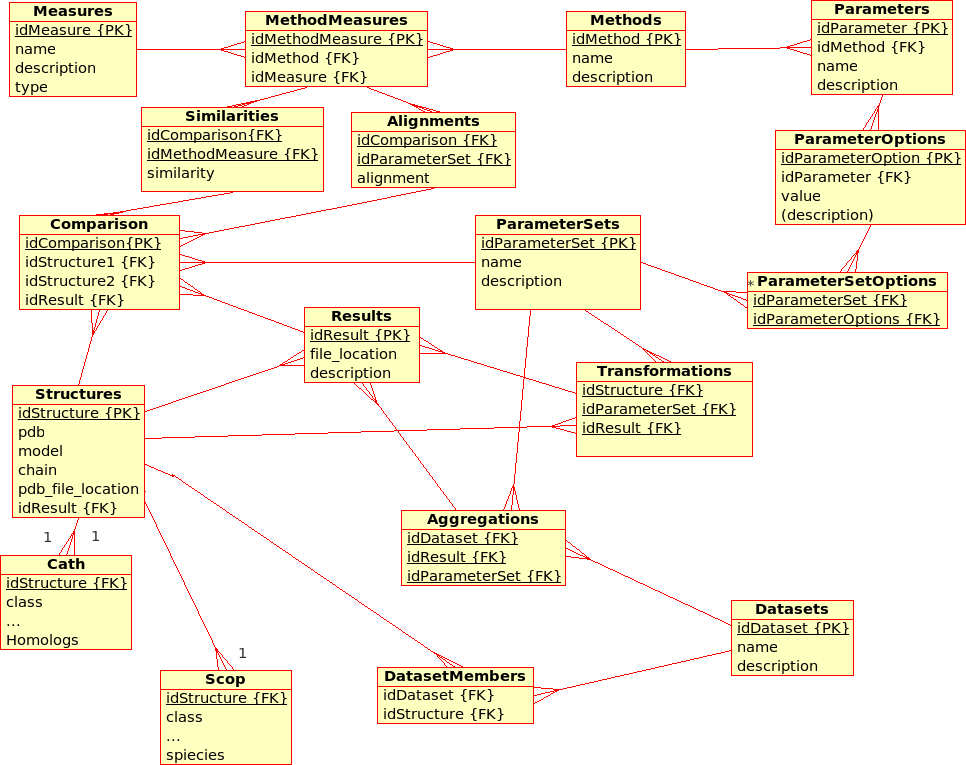
This proposal for an extended database design for the (static) Protein Multiverse aims to include not only ''Comparisons'' but also ''Transformations'' (following the latest development of the I/O specificaitions for the ProCKSI "stand-alone" ''core'' application):
* A ''Transformation'' is a process that derives ONE (main) ''Result'' from ONE single input file.br
Example: The transformation of ''Structure'', ''Tree'', ''!SimilarityMatrix'', etc., using a certain ''Method'' with a certain ''!ParameterSet'', produces a contact map, a tree, ...
* A ''Comparison'' is a process that derives ONE (main) ''Result'' from TWO input files. br
Example The comparison of ''Structures'', ''Trees'', etc., using a ''Method'' with a certain ''!ParameterSet'', produces a similarity value and an alignment
* A ''Composition'' is a process that derives ONE (main) ''Result'' from SEVERAL input files. br
Example The composition of ''!SimilarityMatrices'', ''Trees'', using a ''Method'' with a certain ''!ParameterSet'', produces a consensus similarity matrix, a consensus tree, ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}